My website is practically like it’s own living breathing thing at this point. It’s constantly updating to whatever new knowledge I obtain. Inspired by Tofutush, I thought it be neat to also break down how stuff in my website works. Will not go through everything though because most of it is your typical CSS shenanigans. For this blog post, we’ll be focusing on the Art Archive. It serve as a catalogue for all my art with a simple tag filtering system to boot.## Heads Up! This blog post is by no means a tutorial. The code is oversimplified and a lot of information is omitted for the sake of brevity. Instead of using this as instructions on what to do, you should use this as reference of what you can do. With that disclaimer out of the way, let’s begin!## Listing the Files Above all else we need a list of all files in the art folder. To save us the time from manually typing the filenames, we can just use the command prompt to do it for us. Open up cmd, and head to the path of the art folder. I am technologically illiterate so use I Windows.
cd path\to\folder
Once there, we can use the dir command to list out the files. We need to specify the following switches:
/b- only shows the filenames/s- shows files subdirectories
Type this bad boy into the command line!
dir /b /s
Then the output should be a list that looks something like this:
D:\path\to\folder\filename.jpg
D:\path\to\folder\another-folder\filename.jpg
Copy and paste the output to a separate text editor and just find and replace the D:\path\to\folder\ to an empty string. From there, just convert the output to your chosen text-based data format. I’ll be using json, which I will be calling data from now on. All of the data is stored as an object within an array. Each item should have the bare minimum of a filename.
[
{ "img": "filename.jpg" },
{ "img": "another-folder/2025-filename.jpg" }
]
I also wanted there to be other information as well. Such as a special title, descriptions, other drawings related to it, then tags for a filtering system. So an actual example would look a bit like this.
{
"img": "2025-Psych-Doodles.jpg",
"title": "Doodles of My Silly Lil Guys!!",
"desc": "I made these drawings way back and only decided to color them recently.",
"extra": [
"doodle/2024-Stfu.jpg",
"2025-Psych-Cast.jpg"
],
"tags":"ocs psyche evan jay mary daphne charmaine jian lily august psych"
}
Here’s a breakdown of what each property does
img- the filenametitle- specific titledesc- caption for the artextra- additional imagestags- keywords to categorize art
Actually Using the Data
If you take a look of the example I gave a while back you may notice that all my filenames start with a date.
{ "img": "2025-Psych-Doodles.jpg" }
This is because I want to know what year a drawing was made without having to create a separate property for it. This means that if I want to get the date I have to splice the filename and get the first four characters. I’ll be using javascript to demonstrate all of this.
function getDate(data, i) {
let selected = data[i].img;
return selected.slice(0, 4);
}
Now the code above works fine, under the assumption that the filename always begins with the date. But what happens when the file is inside a folder? So if my img is set to "doodle/2024-Stfu.jpg" the code above will return "dool" as the date. To circumvent this we must get the index of the first instance of the number 2 then slice the string relative to that.
function getDate(data, i) {
let selected = data[i].img;
let index = selected.indexOf("2");
return selected.slice(index, index + 4);
}
Because I am lazy, I don’t want to individually type a title for each art item. Especially since most of it is just going to be the word in the filename anyways. So I wrote a script that will derive a title from the filename when a title isn’t specified.
function getTitle(data, i) {
if (data[i].title !== undefined) {
return data[i].title;
} else {
let title = data[i].img;
// checks if file is inside a folder
if (title.includes("/")) {
title = title.split("/")[1];
}
// removes the date and file extension
title = title.slice(5, title.length - 4);
// replaces all dashed with a whitespace
title = title.replaceAll("-", " ")
return title;
}
}
The desc and extra aren’t necessary so anytime any of those properties are called, there’s a script that checks whether or not they’re defined and only return something if true.
The tags are written as strings because I find writing arrays bothersome. If I want to make that string usable, I will have to split it up into an array using the whitespaces as a separator.
if (data[i].tags) {
tags_list = data[i].tags.split(' ');
}
Additionally I want to be able to automatically add the date and the folder the drawing is in as a tag. So I have to have to obtain that data then merge them all to one big ol array.
// assume this is in a loop
let tags_list = [ date ]
if (data[i].img.includes('/')){
let split = data[i].img.split('/');
let selected = split[split.length - 2];
tags_list.push(selected);
}
if (data[i].tags) {
tags_list = tags_list.concat(data[i].tags.split(' '));
}
Putting Everything Together
Last July, I made a switch to using Static Site Generators (SSGs) - specifically Jekyll. Instead of using javascript to initialize the archive content, I just used Jekyll to process everything beforehand. It loops through the data and adds in the necessary info.
<!-- PS this isn't the actual code -->
{%- for item in site.data.art -%}
<div class="art-archive-item hidden" data-tags="{{ tags_list }}">
<img src="#" data-src="./img/{{ item.img }}" alt="">
<div>
<a href="./~?{{ item.img }}" class="art-archive-comment"></a>
<div class="art-archive-title">{{ item.title }}</div>
{%- if item.desc -%}
<div class="art-archive-desc">{{ item.desc }}</div>
{%- endif -%}
<div class="art-archive-tags">
{%- assign tag_split = tags_list | split: " " -%}
{%- for tag in tag_split -%}
<button onclick="getChecked({{ tag }})">{{ tag }}</button>
{%- endfor -%}
</div>
</div>
</div>
{%- endfor -%}
If you have a keen eye, you may notice that the src of the img tag is set to a hashtag (#) this is because we don’t want all images to load the moment the archive is opened. Forcing a user to load hundreds of images in one go is probably not a very wise idea. We instead store the image link inside of data-src. This way we replace the images src with javascript only when an image needs to be loaded in. We can set up a button that user will click to load more items.
For this to work we need a global counter and the maximum amount of items in the data. Whenever the page loads in or when a user clicks the button, it will update the global counter and loop through a number of items.
var items = document.querySelectorAll('.art-archive > *');
var counter = 0;
var max = items.length;
function showEm (increment) {
let next = counter + increment;
let prev = counter;
// Checks if next value is less than the max
// Otherwise set counter to the max
if ( next <= max ) {
counter = next;
} else {
counter = max;
}
// loops through every item
// Removes the hidden tag and sets image src
for (let i = prev; i < counter; i++) {
let thumb = items[i].querySelector('img');
items[i].classList.remove('hidden');
thumb.src = thumb.dataset.src;
}
}
Filtering System
For the tags, I have a separate yml file that lists out all the available tags.
year:
- '2025'
- '2024'
- '2023'
oc:
- psyche
- evan
- jay
fanart:
- literalhat
- southpark
- insaniquarium
Using that data I write the checkboxes with Jekyll.
<div class="art-archive-options">
{%- assign selected = site.data.art-tags.[include.selected] -%}
{%- for item in selected -%}
<label for="{{ item | downcase }}">
<input type="checkbox" name="{{ include.selected | downcase }}" id="{{ item | downcase }}" value="{{ item | downcase }}">
{%- assign char = item | split: "" | first | upcase -%}
<span>{{ item | slice: 1, item.size | prepend: char | replace: "-", " "}}</span>
</label>
{%- endfor -%}
</div>
We then have a button that will get all the inputs a user checked off. We loop through the selected checkboxes and use the values to add a query to the url.
function getChecked (){
let checked = document.querySelectorAll('input:checked');
let result = "?"
for (let i = 0; i < checked.length ; i++) {
result = result + checked[i].value;
if ( i < checked.length - 1 ) {
result = result + '+';
}
}
window.location.href = result;
}
If the archive is open with a query on the url, then we break that string into an array.
var query = window.location.search.replace("?","");
var tags = query.split("+");
When we loop through all the elements, we get their data-tags then turn it into an array as well
for (let i = 0; i < items.length; i++) {
let data = items[i].dataset.tags.split(" ");
}
Now we have to check whether these two arrays have any similar tags. We could loop through each array item to see if they match, but that process will exponentially get longer with each tag we need to compare. Instead we are going to utilize javascript’s Set object. This is because the values in sets can only occur once. We can use this to identify whether there are any matching tags.
First we merge the two arrays using concat(). Then we use the Set constructor to remove all duplicate tags. Using the size of newly formed set we can compare it to the length of the previous array. If the array had any repeated values, then the set size should be less than the array length.
Additionally we can tell whether or not it fulfills all the tags if the set’s size is equals to the minimum value. To find out the minimum value we must subtract the arrays length to the number of tags in the query.
So in summary, the logic is as follows:
set.size == array.length → no tags matching
set.size < array.length → some tags matching
set.size == array.length - queries.length → all tags matching
My actual implementation for this looks sorta like this:
var items = document.querySelectorAll('.art-archive > *');
var counter = 0;
var max = items.length;
var query = window.location.search.replace("?","");
if (query === ""){
showEm(32); // refer to the script in previous section
} else {
filterEm();
}
function filterEm () {
let tags = query.split('+');
// local counter
let counter = 0;
for (let i = 0; i < items.length; i++) {
let data = items[i].dataset.tags.split(" ");
let mixed = tags.concat(data);
let goal = mixed.length - tags.length;
let set = new Set(mixed).size;
if (set === goal ) {
counter++
items[i].classList.add("all-tags");
} else if (set < mixed.length) {
counter++
items[i].classList.add("not-all-tags");
} else {
items[i].remove()
}
}
max = counter;
items = document.querySelectorAll('.art-archive > *'); // bc handling dom elements r weird
showEm(32);
}
Basically, this loops through all the items then compare the tags in data-tags to the tags in the query. It checks whether or not it has all the tags then it gives it a class according to that (.all-tags or not-all-tags). This is done so that I can implement a “strict mode” that only shows results that fulfills all selected tags.
If none of the tags are fulfilled, the item is removed. After everything is done it changes the global max number, initializes the all the items and fires the showEm() function.
Just like that, the art archive now has a filtering system!! :D
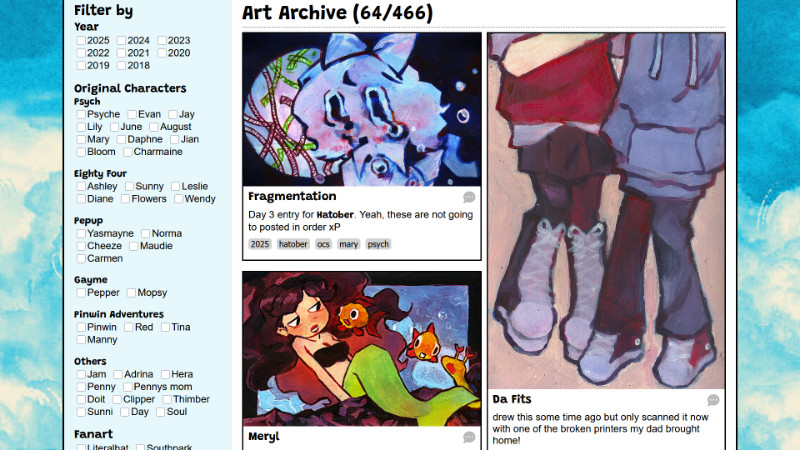
The Cons of this Method
The problem with my filtering system is it’s destructive and inefficient. For example, if a user decides to remove a tag from their initial selection, the page will loop through everything again instead of just looping through the already filtered results.
Despite that, I’ve decided I do not care enough right now and this should be future me’s problem lol. I’m just glad to even have filtering system! If future me is bothered by this inefficiency, then she can put in the work herself!!
View as Individual Post
One last thing before I end this blog post. I wanted there to be a way for people to comment on individual art pieces. With the help of Query Strings and Ayano’s Comment Widget, we can make it seem like we’re opening up a post.
I have an html file that first checks the url if there is any queries available. The query is usually the file name (example: /~?2025-Psych-Doodles.jpg) and if available it will look for the index of that file by looping through the data.
function getIndex(data, current) {
for (let i = 0; i < data.length; i++) {
if (data[i].img === current) {
return i
}
}
return -1
}
You may wonder, Why not just use the index on the query? It’s because I put the most recent drawing on the top the my json file, which means the indexes are constantly changing. Besides, It be a shame if links to a specific art piece get messed up because I moved around the order of the items in the array.
Using the index found, we can basically access all the other properties with the scripts I mentioned above. We can also put a navigation to the images after and before the current index.

Conclusion
Welp, that’s about all of it! As I’ve stated at the start, what I put here isn’t an exact representation of my code. If you want to see what it looks like, feel free to snoop through my actual code. Though, I strongly advise not doing so, since it’s quite a mess. I’d imagine there are more efficient ways off going about all of this, but as it stands this is the method I’ve chosen to go with and I’m pretty contented with it.
[Insert a note from future me cursing past me for this mess of a system]